Hi there,
Welcome back to our series on the future of search! If you missed the last issues, I recommend you read them here and here — otherwise you might be lost during the next few editions…
Here’s a quick TL;DR to help remind you:
- Artificial intelligence is reshaping the way users search on the internet, including the way readers search for books.
- If you want your books to keep being “discoverable” in the future, it’s crucial that you understand how generative search works.
We also established that generative search relies on three fundamental elements:
- Query fan-out: that’s what we discussed last week.
- Vector similarity: that’s on today’s menu.
- Personalization: that’s for… you guessed it: next week.
So without further ado, let’s talk vectors! ↗
Embeddings and vector similarity
Let’s deconstruct how a search — any search — works:
- The user inputs a search query (e.g. “books like game of thrones”);
- The search engine searches through a given dataset (e.g. in the case of an Amazon Kindle Store search, all ebooks on the Kindle Store);
- Among all dataset elements, the search engine retrieves those that they deem most relevant to the search, and may rank them by order of relevance;
- The search engine presents the results (or its answer).
As you may imagine, the most crucial and complex part of this process is the third step: the retrieval of relevant datasets (webpages in Google’s case, or products in Amazon’s case).
In “classic” search, engines relied on metadata like keywords, keyword density, and exact or approximate matches. For example, Amazon search is basically all about finding keyword matches in product titles, keyword metadata, categories, or descriptions. If you search for “small town romance” on the Kindle Store, for example, you’ll see that all the first results feature the search phrase in their titles:
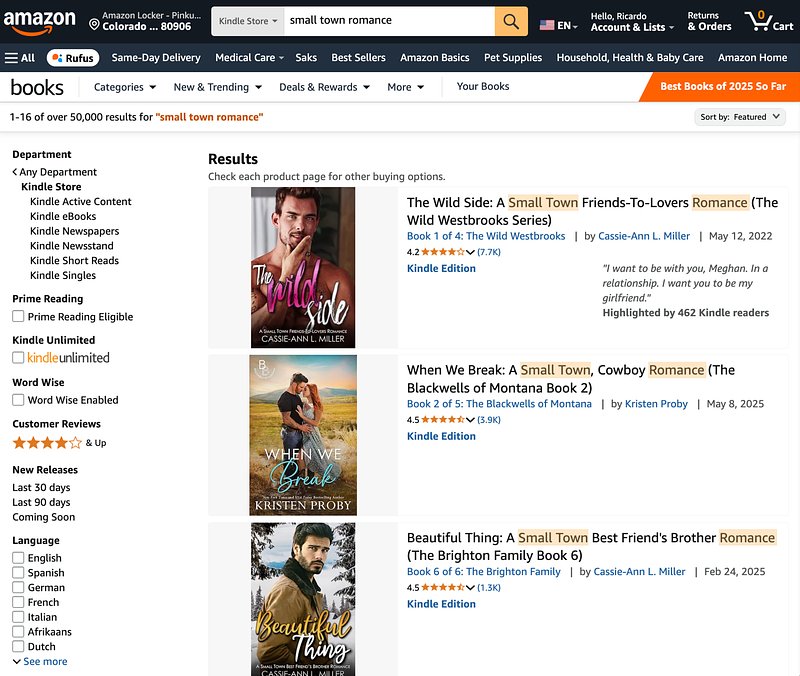
\Note: If you’re curious about how Amazon search algorithms currently work, I have a free course all about that here.
In comparison, LLM-powered search engines rely not on simple metadata, but on vector embeddings. These are essentially numerical representations of data (typically words, phrases, or sentences) which capture semantic meaning and relationships.
I know, that’s awfully abstract. So let’s take an example. The words “king” and “queen” have a relationship: they are both about royalty. But the words “woman” and “queen” also have a relationship: they’re both female.
A vector representation of these words will be able to capture their meanings and relationships:
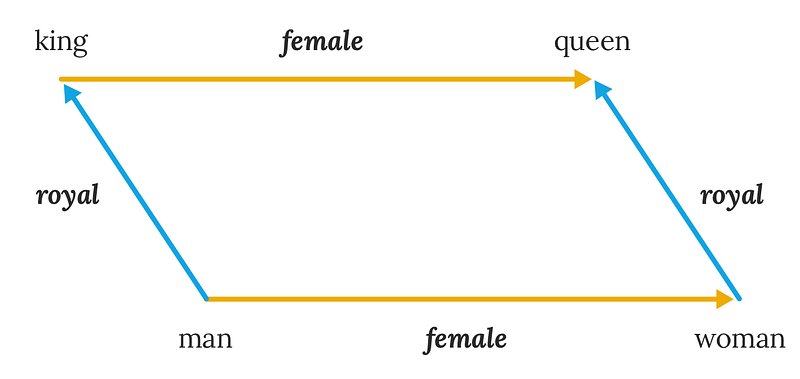
So if I search for a “romantasy with female protagonist,” an LLM-powered search engine will not only pull up books whose descriptions literally mention that, they’ll also be able to pull up books whose protagonist is a “queen” — or even books whose main character has a female-sounding name, or is referred to in the description with female pronouns.
Note: If you want to learn more about vector embeddings and their use in AI models, this Google Cloud article is a good place to start.
This is exactly how Google’s AI Overview and AI Mode search works. The query fan-out process kicks off dozens of related and implied searches, and each of these searches retrieve data (webpages, images, videos, etc.). This data is then analyzed, scored, and ranked based on how its vector embeddings align with the various searches.
If we extrapolate this to Amazon, it’s not hard to imagine a (very near) future where you can search for books in a similar way. In this scenario, Amazon wouldn’t return results based on title match, but based on a semantic analysis of the entire book description, as well as all content surrounding the book (e.g. A+ Content, Amazon reviews, Goodreads reviews, etc.), also-bought data, and more.
As LLM models become more efficient at analyzing large chunks of text, we can even imagine a future where retailers automatically make recommendations based not only on publisher-provided information (book description, A+ content, author bio, etc.) or user-generated content (reviews), but based on the full content of the books themselves.
In other words, retailers would scan all books, generate vector embeddings for all passages, store those in a massive database, and then use that to power their recommendations. This is naturally extremely resource-intensive, and current LLM capacities are not there yet. But five years from now? Who knows.
Vector embeddings aren’t just used to parse and analyse text, they can also be used for images (cue in cover design similarity), or for personal user information. Yes, that’s right: your personal information will be used to return relevant search results to you — in fact, that’s already happening.
But that’s a topic for next week!
Until then, happy writing, and happy marketing,
Ricardo

|
|||
|
Top publishing professionals can help make your writing dreams a reality. Sign up to meet them. |
|
Copyright © 2026 Reedsy, All rights reserved.